Setting Up Kubernetes cluster in AWS (with help of kops)
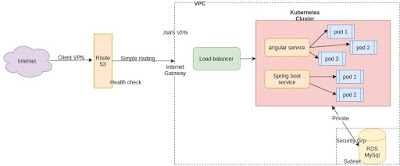
1.Create Ubuntu EC2 instance (befor this create vpc with your range of CIDR and then IAM role Route53, EC2, IAM and S3 full access)
2.install AWSCLI
curl https://s3.amazonaws.com/aws-cli/awscli-bundle.zip -o awscli-bundle.zip
apt install unzip python
unzip awscli-bundle.zip
#sudo apt-get install unzip - if you dont have unzip in your system
./awscli-bundle/install -i /usr/local/aws -b /usr/local/bin/aws
3.Install kubectl
curl -LO https://storage.googleapis.com/kubernetes-release/release/$(curl -s https://storage.googleapis.com/kubernetes-release/release/stable.txt)/bin/linux/amd64/kubectl
chmod +x ./kubectl
sudo mv ./kubectl /usr/local/bin/kubectl
4. aws configure (only give region)
5.Install kops on ubuntu instance:
curl -LO https://github.com/kubernetes/kops/releases/download/$(curl -s https://api.github.com/repos/kubernetes/kops/releases/latest | grep tag_name | cut -d '"' -f 4)/kops-linux-amd64
chmod +x kops-linux-amd64
sudo mv kops-linux-amd64 /usr/local/bin/kops
6.Create a Route53 private hosted zone (you can create Public hosted zone if you have a domain)
7.create an S3 bucket
aws s3 mb s3://k8sbuckettest
8.Expose environment variable:
export KOPS_STATE_STORE=s3://k8sbuckettest
9.Create sshkeys before creating cluster
ssh-keygen
/root/.ssh/id_rsa.pub.
10.Create kubernetes cluster definitions on S3 bucket
kops create cluster --cloud=aws --zones=us-east-2c --name=k8s.trojantest.be --dns-zone=trojantest.be --dns public --master-size=t2.micro --master-count=3 --node-size=t2.micro --node-count=2
11.Create kubernetes cluser
kops update cluster --name k8s.trojantest.be --yes
12. Validate your cluster
kops validate cluster
13. To list nodes
kubectl get nodes
angular.yaml:
apiVersion: apps/v1
kind: Deployment
metadata:
name: angular-deployment
labels:
app: angular
spec:
replicas: 3
selector:
matchLabels:
app: angular
template:
metadata:
labels:
app: angular
spec:
containers:
- name: angular
image: sacoefrancis/angular:v4
ports:
- containerPort: 80
command to run it:
kubectl create -f angular.yaml
angular-service.yaml:
apiVersion: v1
kind: Service
metadata:
name: angular-service
spec:
selector:
app: angular
ports:
- protocol: TCP
port: 80
targetPort: 80
type: LoadBalancer
springboot.yaml:
apiVersion: apps/v1
kind: Deployment
metadata:
name: springboot-deployment
labels:
app: springboot
spec:
replicas: 2
selector:
matchLabels:
app: springboot
template:
metadata:
labels:
app: springboot
spec:
containers:
- name: springboot
image: sacoefrancis/springboot:v4
ports:
- containerPort: 8080
springboot-service.yaml:
apiVersion: v1
kind: Service
metadata:
name: spring-service
spec:
selector:
app: springboot
ports:
- protocol: TCP
port: 8080
targetPort: aa1ef1767cb9646c5bcf367329b21a7a-1651502420.us-east-2.elb.amazonaws.com
type: LoadBalancer
commands:
ssh -i ~/.ssh/id_rsa admin@api.k8s.trojantest.be
kubectl get pods
kubectl get namespaces
kubectl get pods --all-namespaces
kubectl create -f nginx.yaml (running app)
kubectl get pods -o wide
kubectl delete pod nginx-deployment-54f57cf6bf-crvvp
kubectl get pods (gives only services runing)
kubectl delete deployment nginx-deployment
kubectl delete service loadbalancer
kubectl get svc
kops delete cluster k8s.trojantest.be --yes

1.Create Ubuntu EC2 instance (befor this create vpc with your range of CIDR and then IAM role Route53, EC2, IAM and S3 full access)
2.install AWSCLI
curl https://s3.amazonaws.com/aws-cli/awscli-bundle.zip -o awscli-bundle.zip
apt install unzip python
unzip awscli-bundle.zip
#sudo apt-get install unzip - if you dont have unzip in your system
./awscli-bundle/install -i /usr/local/aws -b /usr/local/bin/aws
3.Install kubectl
curl -LO https://storage.googleapis.com/kubernetes-release/release/$(curl -s https://storage.googleapis.com/kubernetes-release/release/stable.txt)/bin/linux/amd64/kubectl
chmod +x ./kubectl
sudo mv ./kubectl /usr/local/bin/kubectl
4. aws configure (only give region)
5.Install kops on ubuntu instance:
curl -LO https://github.com/kubernetes/kops/releases/download/$(curl -s https://api.github.com/repos/kubernetes/kops/releases/latest | grep tag_name | cut -d '"' -f 4)/kops-linux-amd64
chmod +x kops-linux-amd64
sudo mv kops-linux-amd64 /usr/local/bin/kops
6.Create a Route53 private hosted zone (you can create Public hosted zone if you have a domain)
7.create an S3 bucket
aws s3 mb s3://k8sbuckettest
8.Expose environment variable:
export KOPS_STATE_STORE=s3://k8sbuckettest
9.Create sshkeys before creating cluster
ssh-keygen
/root/.ssh/id_rsa.pub.
10.Create kubernetes cluster definitions on S3 bucket
kops create cluster --cloud=aws --zones=us-east-2c --name=k8s.trojantest.be --dns-zone=trojantest.be --dns public --master-size=t2.micro --master-count=3 --node-size=t2.micro --node-count=2
11.Create kubernetes cluser
kops update cluster --name k8s.trojantest.be --yes
12. Validate your cluster
kops validate cluster
13. To list nodes
kubectl get nodes
angular.yaml:
apiVersion: apps/v1
kind: Deployment
metadata:
name: angular-deployment
labels:
app: angular
spec:
replicas: 3
selector:
matchLabels:
app: angular
template:
metadata:
labels:
app: angular
spec:
containers:
- name: angular
image: sacoefrancis/angular:v4
ports:
- containerPort: 80
command to run it:
kubectl create -f angular.yaml
angular-service.yaml:
apiVersion: v1
kind: Service
metadata:
name: angular-service
spec:
selector:
app: angular
ports:
- protocol: TCP
port: 80
targetPort: 80
type: LoadBalancer
springboot.yaml:
apiVersion: apps/v1
kind: Deployment
metadata:
name: springboot-deployment
labels:
app: springboot
spec:
replicas: 2
selector:
matchLabels:
app: springboot
template:
metadata:
labels:
app: springboot
spec:
containers:
- name: springboot
image: sacoefrancis/springboot:v4
ports:
- containerPort: 8080
springboot-service.yaml:
apiVersion: v1
kind: Service
metadata:
name: spring-service
spec:
selector:
app: springboot
ports:
- protocol: TCP
port: 8080
targetPort: aa1ef1767cb9646c5bcf367329b21a7a-1651502420.us-east-2.elb.amazonaws.com
type: LoadBalancer
commands:
ssh -i ~/.ssh/id_rsa admin@api.k8s.trojantest.be
kubectl get pods
kubectl get namespaces
kubectl get pods --all-namespaces
kubectl create -f nginx.yaml (running app)
kubectl get pods -o wide
kubectl delete pod nginx-deployment-54f57cf6bf-crvvp
kubectl get pods (gives only services runing)
kubectl delete deployment nginx-deployment
kubectl delete service loadbalancer
kubectl get svc
kops delete cluster k8s.trojantest.be --yes